Funded by Open Data for Development in Winter 2015
Open North co-led the standards stream of the Open Government Partnership (OGP) Open Data Working Group from 2014-2015. In this capacity, Open Data for Development (OD4D) funded Open North to investigate reporting and analysis practices of OGP members’ open data catalogs, study existing processes to identify gaps and opportunities in how standards are applied and suggest baseline standards and best practices to enhance data usability.
1. Structure
1.1 Catalog Structure
The primary finding is that catalog structure varies greatly between OGP catalogs, with no particular structure emerging as most common. Possible structures include, among others:
- Grouping different formats of the same data: for example, grouping the CSV and Excel formats of a budget table. Offering multiple formats allows data users to use the format that is most accessible to them. Socrata’s software generally follows this structure; for each dataset, all distributions are different formats of the same data: CSV, Excel, JSON and RDF for tabular data and Shapefile and GeoJSON for geospatial data.
- Grouping the same type of data for different periods (longitudinal data): for example, grouping contract disclosures by year. In this structure, the different files could be merged into one file covering all periods. This structure may be used for any classification scheme, e.g. grouping the same type of data for different geographies.
- Grouping different types of data about the same thing: for example, grouping the different tables that make up a national budget. In such cases, the different files could not be merged into one file, as each file has a different structure.
- Grouping an analysis with its supporting data: for example, grouping an environmental impact assessment with its tabular and geospatial data, or grouping a geospatial file with its documentation.
1.2 Data Access Methods
A data access method is a way to retrieve a copy of a file (distribution). OGP catalogs offer several access methods:
- Direct download: A person clicks a link on the catalog’s website, which initiates a download of a data file. We distinguish two types of direct downloads: whether the data file is hosted locally by the catalog or hosted externally by another website. For example, a publisher may upload a spreadsheet to the catalog, in which case it is hosted by the catalog. Alternately, a publisher may already have a spreadsheet hosted on another website; instead of uploading the same spreadsheet to the catalog, they link to the spreadsheet hosted on the other website, thereby avoiding duplication.
- Indirect download: Indirect downloads require an additional step, such as visiting an intermediate web page, creating a user account or filling out a form. In most cases, a person clicks a link on the catalog’s website and is brought to another web page, which may be part of another catalog. From this page, they click a link, which initiates a download of a data file.
- API: In one case, catalogs offer an API that gives programmatic access to data. All Socrata catalogs use the Socrata Open Data API (SODA) and all Open Government Data Initiative (OGDI) catalogs use ODATA. CKAN catalogs using the DataStore extension use the DataStore API; of the 21 CKAN catalogs, 11 use this extension.
- In another case, a person clicks a link on the catalog’s website, which either loads an API’s documentation or submits an API request, returning a JSON response for example. Given the difficulty in identifying such APIs programmatically, an analysis is future work.
1.3 URL Structures
In most cases, a catalog’s software determines, to a great extent, its URL structure. The URL structures of common software are:

2. Meta Data
2.1 Controlled Vocabularies
Within the context of open data catalogs, controlled vocabularies are used to tag properties of catalogs, datasets, and distributions, also known as metadata elements. The vocabularies used by OGP catalogs are:
- The Dublin Core Metadata Initiative (DCMI) Metadata Terms, which have the most widespread adoption of all.
- ISO 19139 Geographic information – Metadata, an XML schema implementation derived from ISO 19115, which has a North American Profile.
- The World Wide Web Consortium’s (W3C) Data Catalog Vocabulary (DCAT), an RDF vocabulary that uses DCMI Metadata Terms and that has many formats, including RDFa in HTML.
- The US Project Open Data (POD) Metadata Schema, a JSON-LD format of DCAT with additional terms.
- Schema.org’s DataCatalog, Dataset and DataDownload schema, which are based on DCAT and which are primarily used as microdata in HTML.
- The US Federal Geographic Data Committee (FGDC) Content Standard for Digital Geospatial Metadata (CSDGM), though agencies are encouraged to transition to ISO.
- The British Standards Institution’s UK GEMINI (GEo-spatial Metadata INteroperability INitiative) specification.
- The DataShare platform’s inventory schema (UK).
- The Infrastructure for Spatial Information in the European Community (INSPIRE).
2.2 Federation
The technology used to federate datasets may be a dynamic API; a static file using any of the vocabularies above; or a Web Accessible Folder (WAF), which is essentially a public directory containing static files. CKAN’s API uses its own, custom vocabulary. The Open Geospatial Consortium’s (OGC) Catalog Service for the Web (CSW) API may use Dublin Core, ISO 19139 or FGDC vocabularies. Of the 22 CKAN and Socrata catalogs, dynamic APIs are used by eight catalogs:
- Catalog Service for the Web (CSW) is used by six catalogs to federate datasets from 39 sources.
- CKAN’s API is used by five catalogs for 7 sources.
- ISO 23950 Information and documentation – Information retrieval (Z39.50) is used by the US catalog for 9 sources.
- The ArcGIS Server REST API is used by the US catalog for 4 sources. Static files are used by the Mexico, UK and US catalogs.
- Mexico uses the Project Open Data Metadata Schema v1.0 for its 13 sources.
- The vocabularies used in the UK for its 34 sources are GEMINI (30), DataShare (2), DCAT as JSON (1) and DCAT as XML/RDF (1).
- The vocabularies used in the US for its 78 sources are Project Open Data Metadata Schema (56), FGDC (21) and ISO 19139 (1). Web Accessible Folders (WAF) are used by the Australia, UK and US catalogs.
- Australia uses ISO 19139 (1).
- The UK uses GEMINI (200).
- The US uses ISO 19139 (153) and FGDC (76). The vocabularies of 232 folders could not be determined automatically, although sampling shows a prevalence of FGDC.
2.3 Metadata Elements
The metadata elements of 27 catalogs were mapped to DCAT to determine the use of each element. The mapping is imperfect as it doesn’t account for all ad-hoc terms used by catalogs for properties. It also could also not account for two differences:
- CKAN and the Project Open Data Metadata Schema track the dataset’s license rather than the distribution’s license like DCAT;
- OpenColibri, the software used by Greece, tracks the distribution’s language rather than the dataset’s language like DCAT.
The usage of dataset elements across all catalogs is below; however, usage varies greatly between catalogs, so a later graph shows usage within each catalog.
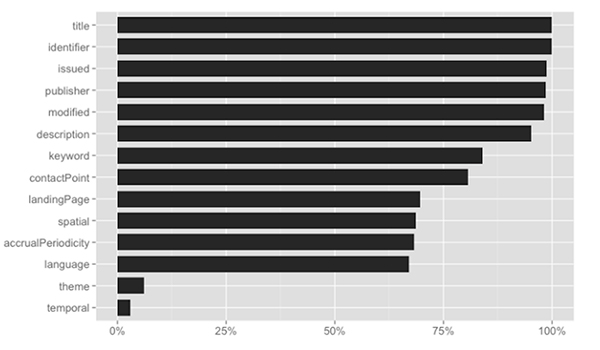
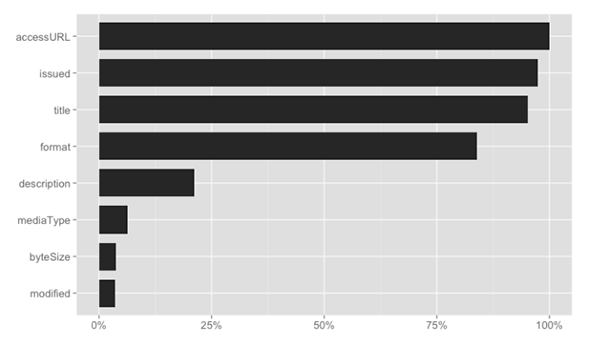
2.4 Metadata Values
Most OGP catalogs, use a combination of metadata elements instead of structured values: for example, Estonia combines contact-name, contact-email and contact-phone for contact point, and Paraguay combines valid_from and valid_until for temporal extent. This is likely due to it being easier in CKAN to add a simple text field than to add a field containing subfields, which would introduce more structure.
3. Data
3.1 File Formats
Automated scripts were developed and used to collect the media types of all distributions in all 22 CKAN and Socrata catalogs, plus those of Spain and Greece. Socrata catalogs always provide a media type. CKAN catalogs, on the other hand, provide a media type for 6% of distributions, because publishers cannot set it via CKAN’s web forms. The scripts therefore had to determine the media type based on the non-standardized format description and based on the access URL’s extension; if the two conflicted, no media type was set. As future work, the scripts may instead determine the media type by downloading the file. After collecting all media types, any non-IANA media types were normalized to a single form. By the end of this process, 79% of the 1.5 million distributions had normalized media types.
3.2 Character Encodings
The literature review found only one country with official guidance on encoding: the UK. While our analysis methods need improvement to identify the encoding of a greater share of the CSV files, it is clear that a lack of encoding information and an inconsistent use of encodings are common issues across catalogs.
4. Licensing and Rights
4.1 Licenses and public domain dedications
The following graph shows the proportion of datasets per catalog with an unspecified or underspecified license.
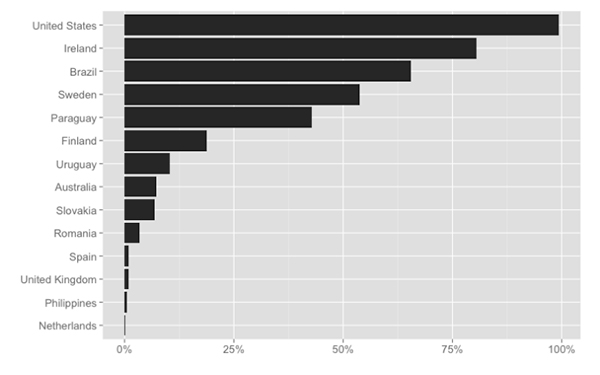
4.2 Licensing and Rights Meta Data
Data catalogs provide little to no metadata about licenses and rights statements. The only common metadata are the title of the license and the URL to its full text. CKAN also provides a license identifier and an “isopen” boolean indicating whether the license is an open license according to the Open Definition. However, many catalogs misconfigure the “isopen” boolean, i.e. the metadata is unreliable.