Introduction
Preliminary report for IRCC submitted by Open North on March 31, 2016 Updated: April 29, 2016
Immigration, Refugees and Citizenship Canada (IRCC) contracted the services of Open North to conduct a small study to better understand the needs of existing and potential users of open data as released by IRCC on open.canada.ca, and to inform ongoing efforts to unlock the potential applications of open data to support newcomer settlement and integration in Canada.
Open North is a Canadian non-profit organization that creates online tools to educate and empower citizens to participate actively in democracy, and has established itself as a Canadian leader in open government and open data, and particularly in research on open data.
Methodology
Step 1: Qualitative
Open North designed a data user questionnaire (see Annex 1) specifically for this study, which covers a range of non-technical and technical issues. The online questionnaire comprised of 48 questions was sent to a list of fifteen stakeholders (e.g. employers, settlement service providers, academia, government) provided by IRCC.
The survey completion guidelines encouraged stakeholders to consult individuals within their respective organizations who are responsible for compiling research, inputting data into data management systems, writing reports, creating online tools and services, or who are involved in the use and management of data and information. Open North was available to answer the questions of stakeholders, if necessary.
Of the list of fifteen stakeholders, eight completed surveys were collected, including two submissions by different individuals from the same organization.
Step 2: Quantitative
To participate in this study, the stakeholders were also asked to participate in a one-hour discussion group. The discussion groups were designed to delve deeper into the survey responses and create an opportunity to highlight key recommendations for IRCC from the perspective of data users.
Participating Organizations
Every organization listed below agreed to be listed as participants in the study.
- Immigrant Services Association of Nova Scotia
- Immigration Research West/University of Manitoba
- Tourism HR Canada
- Peel Newcomer Strategy Group
- Toronto Region Immigrant Employment Council
- MOSAIC
- City of Vancouver
A data hungry stakeholder community
All stakeholders view data as essential (fairly important, or very important) in carrying out their mission and work, and all have several staff members dedicated to collecting, assembling and analyzing data. In some cases, those responsibilities are shared between different staff members. As one stakeholder put it, demographic facts are essentially the foundation of any research on immigration. They turn to data in order to see what’s actually going on on the ground and to understand the trends and gaps in services available to refugees and newcomers. Moreover, data directs strategic decision-making for seven out of the eight stakeholders surveyed. From the data, they can then develop policies and programs, plan accordingly and further evaluate their activities
Importantly, stakeholders rely on data from multiple sources. All participating stakeholders indicated that they use data produced by the federal government and academic sources, as well as data that they collect themselves. Seven out of the eight stakeholders surveyed also rely on provincial data. Data from IRCC, Statistics Canada, Canadian Human Rights Commission datasets are deemed very important and important among known federal government data sources. Geomatics Canada and Natural Resources Canada scored the lowest.
In order of importance, stakeholders identified the following five IRCC datasets (ranked as very important or fairly important) from the ten data sets listed in the online survey:
- Facts & Figures 2014: Immigration Overview – Permanent Residents
- Permanent residents by province or territory and urban area
- Permanent residents by category, 1980 – 2015
- Permanent Residents by Country of Citizenship, 1980 – 2015
- Permanent Residents by Country of Citizenship, Q1 2014 – Q4 2015
Other IRCC datasets of particular significance to the stakeholders not listed in that question include: iCARE, IMDB, HArts data, longitudinal survey of immigrants to Canada, and General Social Survey data about integration and foreign-born populations. When asked to identify other government departments whose data sources are very or fairly important to their organization, stakeholders identified labour market information and SSHRC data designed to specifically address immigration and settlement of newcomers.
Recommendations
1. Stakeholders, especially academics and service providers, were also interested in qualitative data as a complementary source of information that helps contextualize quantitative datasets and their analysis, as well as the experience of service users.
a. For example, IRCC could support community based research initiatives designed to situate and communicate the experience of service users and the impact of the integration process.
2. IRCC could feature new datasets and promote innovative uses of its datasets to connect data users supporting newcomers and refugees. For example, IRCC could feature narrative stories of data users and their respective solutions in response to specific problems.
a. Examples: New York City
3. As part of this effort, IRCC could support web-based repositories, like GitHub, to facilitate the exchange of source code among developers and data analysts resolving common issues.
a. Examples of government initiated GitHub initiatives include: United Kingdom, United States, Australia, New Zealand, and the Province of British Columbia.
2. Issues of discoverability
When familiar with the IRCC’s catalog (as listed on the Open Government portal at open.canada.ca) — which was not the case for all — several stakeholders noted that the catalog is not only difficult to navigate, but that the open data source is not widely known as well. Indeed, there seems to be very limited knowledge about open data itself among stakeholders, as indicated by the chart below:
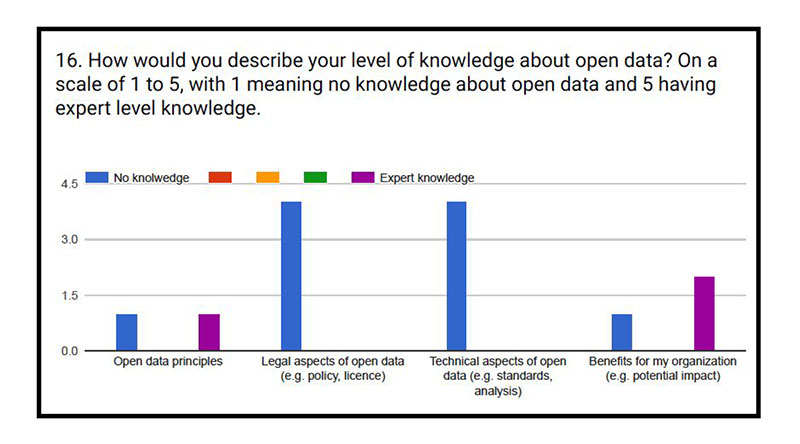
Above all, it seems that there is no way for respondents to really know if the data available on the open data portal is up to date or not, and whether it truly reflects the situation on the ground at that moment. Several respondents seemed to assume that the data is timely, while only two believed it is. Furthermore, most respondents did not know if whole actual datasets were accessible or not, nor why they ceased to be accessible.
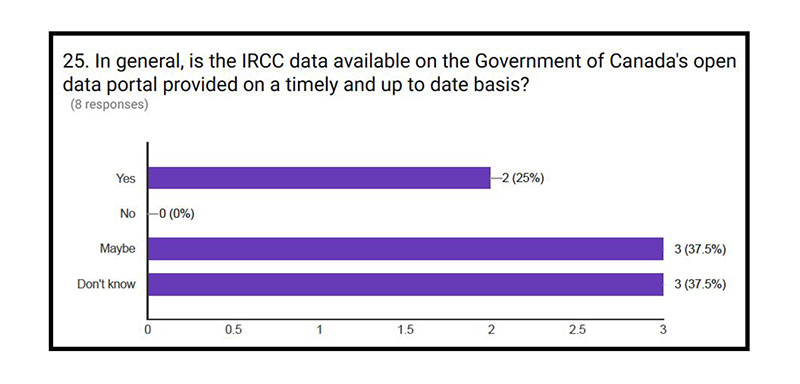
Specifically, The Facts and Figures dataset was cited as an example by several stakeholders. It was unclear why that dataset ceased to include numbers and percentages or to be updated.
With regards to metadata[1], the simplest route is usually the best option: the title and descriptions are the two most important features of the metadata according to the respondents They are the two characteristics that offer up the most amount of information in the least amount of time. Unfortunately, most of the respondents raised several issues concerning the completeness, accuracy and accessibility of the metadata published.
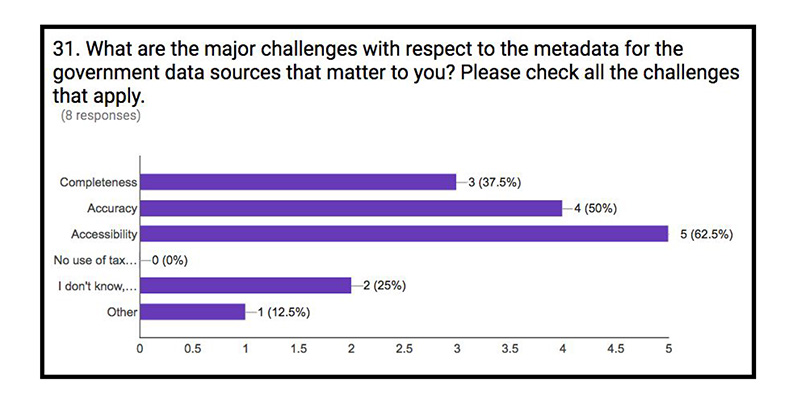
[1] Metadata is the data providing information about one or more aspects of data within a dataset. It is used to summarize basic information about data, which can make it easier to track and work with specific data. Core metadata is a limited set of metadata which provides important, fundamental information about data, and should be defined by a consistent vocabulary across all datasets. Core metadata elements may include the dataset title, source, publication date, and format, as well as other relevant information that describes the dataset and supports discoverability (that is, makes it easier to search for and find the dataset).
Recommendations
4. IRCC could make available a complete list of its data assets (including open, and not yet open, data and information)and establish a public engagement mechanism to systematically prioritize the sequence of its release. This would enhance predictability as well as an appreciation of how limited resources at IRCC are allocated to meet this demand;
5. When datasets are no longer available, an explanation should be provided to explain why that is the case, and what changes were made to the data collection methodology to support data users in adjusting their applications of the data set(s);
6. IRCC could increase the use of Linked Data[2] to enhance the discoverability and access of relevant and related sources of information, analysis, and raw data.
[2] Linked Data is a method of publishing structured data so that it can be interlinked and become more useful through semantic queries. It builds upon standard Web technologies such as HTTP, RDF and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a way that can be read automatically by computers. This enables data from different sources to be connected and queried. See: http://linkeddata.org/ and https://www.w3.org/wiki/LinkedData
3. Gaps in data offerings
As the majority of the stakeholders surveyed are province-based organizations working to integrate immigrants within their regions (i.e. these are not national organizations), one of the glaring absences in regards to the data available is provincial and municipal data, either produced by these orders of government, or available by breakdown at the provincial and municipal levels. In some cases, data doesn’t have the level of granularity that is required to conduct useful analysis at the local level. Respondents brought up the fact that the lack of data concerning provincial health records, labour market assessments, Express Entry recipients, permanent residents and interprovincial mobility have left them scrambling to find data elsewhere in order to get a more complete picture. For example, in the case of Express Entry, an interviewee identified several complementary data sources: socio-demographic information about applicants, invitees, visa recipients, system performance indicators.
First time that data on immigrants is being collected. What data could be mined? Who is applying? Who gets an invitation? Who gets a visa? (demographic information, and points). What is the efficacy of this system?
Data granularity is also problematic in some parts of the country, like the Atlantic provinces, where labour force and immigration survey data are lumped together. Enabling settlement organizations to track the movement of populations through the analysis of data sources on the demand for services is also problematic.
Tracking the experience of refugees after their one-year residency status in Canada is especially problematic. It is very difficult to track which services they access, or try to access, such as SIN applications or health coverage. This lack of data impacts resource allocations and the ability of government and settlement organizations to better understand populations that sometimes move frequently from one location to another.
Part of this problem is the inability to classify the data by geographical locations, a feature that reportedly used to be possible, but that is not available on the open data site. Consequently, fewer tables can now be produced than before. Unavailable statistics about landed immigrants was also mentioned. Stakeholders were furthermore interested in gaining access to datasets that measure the performance of government programs (e.g. refugee and immigration boards) to help contextualise their analysis and the situation of newcomers and refugees.
All stakeholders noted the negative impact of the abolition of the census by the previous federal government. The community counts data was highly valued by stakeholders.
Recommendations
7. Data collection methodologies could be revised to accord for a higher level of granularity at the local level where it is often needed the most by settlement organizations and government;
8. All stakeholders would welcome opportunities to participate in the design stage of government-led research projects. Such an initiative would not only serve to provide data that is more useful, but also increase predictability in future sources of data that would facilitate forward planning processes;
9. IRCC could make its’ grants and contributions data publicly available to enable Canadians and stakeholders to better understand IRCC spending in support of newcomers and refugees and program measurement indicators. This data would enable the sector engage in solution-finding and partner with government on social policy objectives[3]
[3] See: http://odimpact.org/case-opening-canadas-t3010-charity-information-return-data.html and http://open.canada.ca/en/idea/develop-open-data-standard-grants-contributions-data
4. Maze of communication
Whether it is to ask questions, confirm interpretations, discuss applications or to report errors, all respondents have needed at one point or another to contact someone responsible for the data. What stands out from the online survey, however, is that there does not seem to be one standard method of engagement. Indeed, several have used online forms, social media, mailing lists and other ways to engage with people responsible for the data.
That being said, more than one respondent brought up the issue of feedback. There is currently no way to constructively provide IRCC with feedback. The inability to contextualise IRCC data is an impediment to innovation within the settlement and newcomer sector. Stakeholders were calling for an open data approach that went beyond the supply and demand model for one that factored the context of data users and producers.[4] One respondent suggested a forum in order to increase collaboration between the research community, stakeholder organizations and IRCC.
[4] See: http://www.nesta.org.uk/blog/data-innovation-where-start-road-less-taken
Another remarked that simple updates when new datasets are available would be useful.
The example of how IRCC tracked the arrival of Syrian refugees was praised, especially by settlement organizations. The access to frequently updated data such as the plane number, arrival schedules, number of passengers on each plane, which was presented on an interactive map, helped stakeholders plan their responses. However, as one stakeholder observed, it has become difficult to track the whereabouts of refugees after they arrive. This is especially the case for privately sponsored refugees.
Recommendations
10. Sharing the contact details of IRCC data producers and managers and putting in place engagement protocols (e.g. timely response times, making responses to data requests available online) would help strengthen feedback loops;
11. IRCC could improve the standardization of its metadata. The sample of stakeholders for this study was too small to determine which metadata would be most useful. Basic information like the publication date, when it was updated, spatial coverage, and key words seem to be in highest demand;
12. Data visualisations and multi-layered assemblage of geospatial data or linked data seem to be in demand by stakeholders to better understand the situation of refugees and newcomers in Canada.
13. There are untapped communities of practice, such as local civic tech communities and designers. Collaborative models of co-creation remain unexplored and the IRCC should take stock of the shortcomings of the hackathon model. [5]
[5] For a good critique of hackathons, see: So You Think That You Want to Run a Hackathon: Think Again, Medium, Laurenellen McCann, 24 June 2016
5. Literacy and capacity issues
Stakeholders’ levels of literacy with regards to the legal and technical aspects of open data seem to be fairly low. They readily admit that they are unaware of the licensing issues around open data, which, as far as the interview process could determine, did not indicate any problematic uses of government data. For example, six out of the eight respondents said that they were not at all familiar with the Version 2.0 of the Open Government Licence which governs the terms of use of open government data. It is important to note that this raises an interesting paradox: while most respondents say that they have knowledge of open data principles, many of them are not actually aware of the terms of use, nor how the data is produced and by whom.
When it comes to technical literacy, most respondents seem to have difficulty forming an opinion on data encoding and data formats, so much so that most cannot seem to identify specific challenges regarding these issues. However, one thing is clear: most respondents are seeking a better standardization process and a more user-friendly interface. The inability of settlement organizations to distinguish between accessing an Application Programming Interface (API) [6] compared to direct download was indicative of a capacity gap. Some basic, user-friendly, educational tools (see Edmonton’s video tutorials, for example [7]) are increasingly made available on open data portals to support data users.
Building on the experience of initiatives like the Data Capacity Table, a settlement organization observed that the federal government (in partnership with other levels of government) is better positioned to bring stakeholders together to discuss ethical issues relevant to data, gaps, and opportunities to refine data collection. An interviewee observed that service providers often do not know the researchers in their fields and vice versa. There was interest in integrating research and community organizations in establishing research partnership tables (such as the one established in 2014). This model was effective in helping government develop more useful information.
[6] API is a set of routines, protocols, and tools for building software applications. The API specifies how software components should interact and APIs are used when programming graphical user interface components. A good API makes it easier to develop a program by providing all the building blocks. A programmer then puts the blocks together. Few nonprofits have the latter capacity.
[7] https://data.edmonton.ca/videos
Recommendations
14. Stakeholders would welcome investments in data literacy programs (including open data principles, and technical skills and knowledge) for front-line organizations, as long as it doesn’t pull them away from service delivery. Investments should be made to increase capacity, not try to do more with less;
15. IRCC could standardize access to data from organizations that it funds, which would be especially useful from a policy development perspective. Sharing data [8] could eventually lead to open data. To this end, it’s important to adopt an inclusive approach with stakeholders expected to share information as sharing data successfully depends on collaboratively establishing enabling conditions to overcome perceptions of risk and barriers.
16. Moreover, service providers collect a lot of data but do not share it effectively among themselves, often replicating informational silos within government. Third parties with expert knowledge of data management may be better positioned than government to facilitate a shared data culture. IRCC could engage stakeholders to identify and address related mindset shifts issues;
17. Government could provide online tutorials or toolkits (e.g. on how to use APIs for example) to help settlement and newcomer service providers use and manipulate multiple sources of data effectively. APIs enable developers to embed and use our data in their applications to build highly functional data-driven applications, and to analyze and interpret the data more effectively, among other reasons.
[8] In cases where data cannot be made open, it may instead be closed data (which can be accessed only by the data subject, owner, or holder) or shared data (which is accessible beyond its subject, owner, or holder, but is only accessible to a limited group of people or organizations). For more information about the data spectrum, see the Open Data Institute Open Data Spectrum, which illustrates the different types or levels of openness of data.